© 2025 Kênh Chuỗi Khối Việt . All Rights Reserved.
Trận Đánh Lực Lượng Trí Tuệ Nhân Tạo của Trung Quốc
Tám năm trước, trái tim của ZTE đã ngừng đập.
Vào ngày 16 tháng 4 năm 2018, một lệnh cấm từ Sở Công nghiệp và An ninh của Bộ Thương mại Hoa Kỳ đã khiến ZTE Corporation, một trong bốn công ty thiết bị viễn thông lớn nhất thế giới với 80,000 nhân viên và doanh thu hàng năm hơn 100 tỷ đô la, đột ngột đóng cửa. Lệnh cấm rất đơn giản, trong 7 năm tới, mọi công ty Hoa Kỳ sẽ bị cấm bán linh kiện, hàng hóa, phần mềm và công nghệ cho ZTE.
Mất chip của Qualcomm, trạm cơ sở ngừng sản xuất. Thiếu bản quyền Android từ Google, điện thoại cũng không còn hệ điều hành để sử dụng. 23 ngày sau, ZTE phát đi thông cáo cho biết hoạt động kinh doanh chính của công ty không còn khả thi.
Tuy nhiên, ZTE cuối cùng đã sống sót, nhưng giá phải trả là 14 tỷ đô la.
Phạt 10 tỷ đô la, thanh toán một lần; 4 tỷ đô la tiền đặt cọc, gửi vào tài khoản ngân hàng trữ giữ tại Mỹ. Ngoài ra, toàn bộ ban lãnh đạo đã được thay đổi, chấp nhận sự giám sát tuân thủ của đội ngũ của Mỹ. Trong năm 2018, ZTE lỗ ròng 7 tỷ NHân dân tệ, doanh thu giảm mạnh 21.4% so với cùng kỳ năm trước.
Trong bức thư nội bộ, cựu Chủ tịch ZTE, Ông Yimin Yin viết rằng: "Chúng ta đang hoạt động trong một ngành công nghiệp phức tạp, phụ thuộc cao vào chuỗi cung ứng toàn cầu." Câu này, vào thời điểm đó, vừa là cảm xúc và vô phương cứu chữa.
Tám năm sau, vào ngày 26 tháng 2 năm 2026, con "kỳ lân" trí tuệ nhân tạo của Trung Quốc, DeepSeek, tuyên bố rằng mô hình lớn đa phương tiện V4 sắp ra mắt của họ sẽ ưu tiên hợp tác sâu hơn với các nhà sản xuất chip trong nước, lần đầu tiên thực hiện một giải pháp không phải từ Nvidia từ quá trình tiền huấn luyện đến điều chỉnh cuối cùng.
Dịch nghĩa là: Chúng ta sẽ không sử dụng Nvidia nữa.
Ngay sau khi tin tức được công bố, phản ứng ban đầu của thị trường là hoài nghi. Nvidia chiếm hơn 90% thị phần trên toàn cầu trong thị trường chip huấn luyện trí tuệ nhân tạo, bỏ qua nó, điều này có lý do kinh doanh không?
Nhưng phía sau lựa chọn của DeepSeek, ẩn chứa một vấn đề lớn hơn cả logic kinh doanh: trí tuệ nhân tạo của Trung Quốc cần một cuộc đấu tranh sức mạnh tính toán như thế nào?
Nhiều người nghĩ rằng, lệnh cấm chip đã làm kẹt đứng phần cứng. Nhưng thực sự khiến các công ty trí tuệ nhân tạo Trung Quốc cảm thấy nghẹt thở, là một thứ tên là CUDA.
CUDA, viết tắt của Compute Unified Device Architecture, là nền tảng tính toán song song và mô hình lập trình mà Nvidia đã phát hành vào năm 2006. Nó cho phép nhà phát triển trực tiếp sử dụng sức mạnh tính toán của GPU của Nvidia để tăng tốc nhiều nhiệm vụ tính toán phức tạp.
Trước khi thời đại AI đến, đây chỉ là một công cụ dành cho một số ít những người đam mê công nghệ. Nhưng khi sóng lớn Học sâu đổ bộ, CUDA đã trở thành nền tảng của toàn bộ ngành công nghiệp AI.
Việc huấn luyện Mô hình AI lớn về bản chất là các phép toán ma trận khổng lồ. Điều này chính là công việc mà GPU làm tốt nhất.
NVIDIA với việc chuẩn bị trước đó hàng chục năm, đã xây dựng cho các nhà phát triển AI trên toàn cầu một bộ công cụ hoàn chỉnh từ phần cứng cơ bản đến ứng dụng cao cấp thông qua CUDA. Hiện nay, tất cả các framework AI phổ biến trên toàn cầu, từ TensorFlow của Google đến PyTorch của Meta, đều chặt chẽ liên kết với CUDA ở tầng thấp.
Một sinh viên tiến sĩ AI, từ ngày đầu nhập học, đã học tập, lập trình và thực nghiệm trong môi trường CUDA. Mỗi dòng mã mà anh ta viết đều củng cố Thành Cổ của NVIDIA.
Đến năm 2025, hệ sinh thái CUDA đã có hơn 4,5 triệu nhà phát triển, bao gồm hơn 3000 ứng dụng tăng tốc GPU, hơn 40.000 công ty trên toàn cầu đang sử dụng CUDA. Con số này có nghĩa là hơn 90% nhà phát triển AI trên toàn cầu đều ràng buộc trong hệ sinh thái của NVIDIA.
Điều đáng sợ của CUDA là nó giống như một bánh xe cánh quạt. Ngày càng có nhiều nhà phát triển sử dụng, sẽ tạo ra nhiều công cụ, thư viện và mã nguồn, hệ sinh thái càng phồn thịnh; hệ sinh thái càng phồn thịnh, càng thu hút thêm nhiều nhà phát triển tham gia. Một khi bánh xe cánh quạt này quay, nó gần như không thể bị xao lạc.
Kết quả là, NVIDIA bán cho bạn chiếc xẻng đắt tiền nhất, và đồng thời định nghĩa duy nhất cách đào. Bạn muốn đổi một cái xẻng khác? Được, nhưng trước hết bạn phải viết lại tất cả kinh nghiệm, công cụ và mã nguồn mà hàng trăm nghìn bộ não thông minh nhất trong vài chục năm qua trên toàn cầu tích luỹ dưới tư duy này.
Chi phí này, ai sẽ trả?
Do đó, khi vào ngày 7 tháng 10 năm 2022, vòng đầu tiên của việc kiểm soát của BIS được triển khai, hạn chế xuất khẩu A100 và H100 của NVIDIA đến Trung Quốc, các công ty AI của Trung Quốc lần đầu tiên cảm nhận được sự hầm hố theo kiểu ZTE. Sau đó, NVIDIA đã tung ra phiên bản "Dành Riêng Cho Trung Quốc" của A800 và H800, giảm băng thông liên kết giữa chip để duy trì cung cấp đầy đủ.
Nhưng chỉ sau một năm, vào ngày 17 tháng 10 năm 2023, vòng kiểm soát thứ hai lại được siết chặt, A800 và H800 cũng bị cấm, 13 công ty Trung Quốc bị liệt kê vào Danh sách Thực thể. NVIDIA buộc phải tung ra phiên bản H20 được cắt giảm hơn. Đến tháng 12 năm 2024, vòng kiểm soát cuối cùng trong nhiệm kỳ của chính phủ Biden đã được triển khai, thậm chí việc xuất khẩu H20 cũng bị hạn chế nghiêm ngặt.
Kiểm soát ba tầng, tăng cường từng bước.
Nhưng lần này, diễn biến của câu chuyện, và với ZTE năm xưa hoàn toàn khác biệt.
Dưới lệnh cấm, mọi người đều nghĩ rằng ước mơ về mô hình lớn của Trung Quốc AI sẽ chấm dứt ở đây.
Chúng đều nhầm. Đối mặt với sự chặn đứng, các công ty Trung Quốc đã không chọn cách đấu tranh trực diện, mà bắt đầu một cuộc đột phá. Trận chiến đầu tiên của cuộc đột phá này không phải ở chip, mà ở thuật toán.
Từ cuối năm 2024 đến năm 2025, các công ty AI của Trung Quốc đồng loạt chuyển hướng sang một hướng công nghệ: Mô hình chuyên gia kết hợp.
Đơn giản chỉ là chia một mô hình lớn thành nhiều chuyên gia nhỏ, chỉ kích hoạt một số chuyên gia liên quan nhất khi xử lý nhiệm vụ, thay vì để cả mô hình chạy.
V3 của DeepSeek chính là một đại diện điển hình của tư duy này. Nó có 671 tỷ tham số, nhưng mỗi lần suy luận chỉ kích hoạt 370 tỷ trong số đó, chỉ chiếm 5,5% tổng số. Về chi phí huấn luyện, nó sử dụng 2048 GPU Nvidia H800, huấn luyện trong 58 ngày, tổng chi phí 557,6 triệu USD. So sánh với ước lượng chi phí huấn luyện GPT-4, khoảng 78 triệu USD. Một khác biệt về tầm quan trọng.
Việc tối ưu hóa thuật toán tạo ra ảnh hưởng trực tiếp đến giá cả. Giá API của DeepSeek, 0,028 đến 0,28 USD cho mỗi triệu Token đầu vào, đầu ra 0,42 USD. Trong khi giá đầu vào của GPT-4o là 5 USD, đầu ra 15 USD. Claude Opus đắt đỏ hơn, đầu vào 15 USD, đầu ra 75 USD. Chuyển sang, DeepSeek rẻ hơn Claude từ 25 đến 75 lần.
Sự chênh lệch giá này đã gây ra sự chấn động lớn trên thị trường phát triển toàn cầu. Vào tháng 2 năm 2026, trên OpenRouter, nền tảng tổng hợp API mô hình AI lớn nhất thế giới, lượng cuộc gọi hàng tuần của các mô hình AI Trung Quốc đã tăng mạnh 127% trong ba tuần, vượt qua Mỹ lần đầu tiên. Một năm trước, thị phần của mô hình Trung Quốc trên OpenRouter không đến 2%. Một năm sau, tăng 421%, tiệm cận 60%.
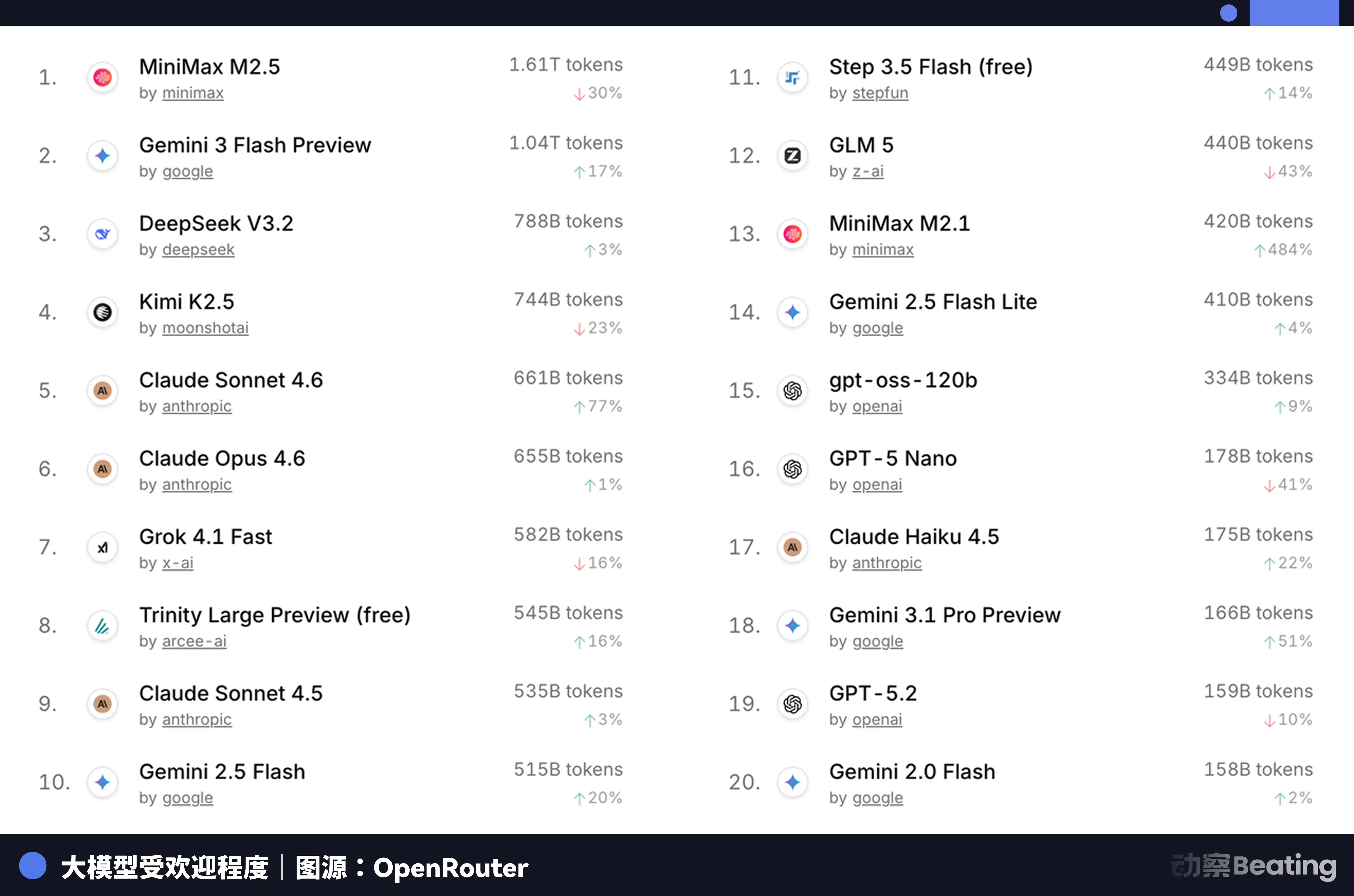
Đằng sau tập dữ liệu này, có một sự thay đổi cấu trúc dễ bị bỏ qua. Bắt đầu từ cuối năm 2025, kịch bản ứng dụng AI chính thức đã chuyển từ trò chuyện sang Agent. Trong kịch bản Agent, lượng Token tiêu thụ cho mỗi nhiệm vụ tăng từ 10 đến 100 lần so với trò chuyện đơn giản. Khi lượng tiêu thụ Token tăng theo cấp số nhân, giá cả trở thành yếu tố quyết định. Tính hiệu quả giá của mô hình Trung Quốc, một cách hoàn hảo đã nắm bắt cửa sổ này.
Tuy nhiên, vấn đề là việc giảm chi phí suy luận không giải quyết được vấn đề cơ bản của việc huấn luyện. Một mô hình lớn nếu không thể tiếp tục được huấn luyện và cập nhật trên dữ liệu mới nhất, khả năng của nó sẽ nhanh chóng suy giảm. Và việc huấn luyện vẫn là hố đen về sức mạnh tính toán mà không thể tránh khỏi.
Vậy, "cào soil" cho việc huấn luyện đến từ đâu?
Xinghua, Huyện nho nhỏ ở Trung Quảng, nổi tiếng với thép không gỉ và thực phẩm lành mạnh, trước đây không liên quan đến trí tuệ nhân tạo. Nhưng vào năm 2025, một dây chuyền sản xuất máy chủ có năng lực tính toán nội địa dài 148 mét đã được xây dựng và đưa vào hoạt động tại đây, từ việc ký hợp đồng đến đưa vào hoạt động chỉ mất 180 ngày.
Lõi của dây chuyền này là hai vi mạch hoàn toàn nội địa: bộ xử lý Loongson 3C6000 và Thẻ Tăng tốc Trí tuệ Nhân tạo Tai Chu Ngọc Thái Thủ. Loongson 3C6000, từ tập lệnh đến kiến trúc nhỏ tự chủ hoàn toàn. Tai Chu Ngọc Thái Thủ xuất phát từ Trung tâm Siêu tính quốc gia Vô Tý và đội ngũ Đại học Thanh Hóa, sử dụng kiến trúc nhiều nhân không đồng nhất.
Khi dây chuyền này hoạt động đạt công suất tối đa, 5 phút xuống dãy một máy chủ, tổng vốn đầu tư của dây chuyền sản xuất này là 11 tỷ nhân dân tệ, dự kiến sản xuất 100.000 máy chủ mỗi năm.
Quan trọng hơn, dựa trên cụm vi mạch nội địa này, đã bắt đầu đảm nhận nhiệm vụ huấn luyện mô hình lớn thực sự.
Vào tháng 1 năm 2026, SmartSpec AI phối hợp với Huawei đã phát hành GLM-Image, đây là mô hình tạo ảnh SOTA đầu tiên được huấn luyện hoàn toàn dựa trên vi mạch nội địa. Tháng 2, mô hình lớn cỡ tỷ của China Telecom, trên cụm sức mạnh tính toán vạn thẻ nội địa tại Thượng Hải Lâm Cảng hoàn thành quá trình huấn luyện toàn diện.
Ý nghĩa của những ví dụ này đó là, chúng chứng minh điều gì: vi mạch nội địa, đã từ "có thể sử dụng cho suy luận" bước sang "có thể sử dụng cho huấn luyện". Đây là sự thay đổi về chất. Suy luận chỉ cần chạy mô hình đã được huấn luyện, yêu cầu về vi mạch tương đối thấp; trong khi huấn luyện cần xử lý lượng lớn dữ liệu, thực hiện tính toán độ dốc phức tạp và cập nhật thông số, yêu cầu về sức mạnh tính toán của vi mạch, băng thông kết nối và hệ sinh thái phần mềm, cao hơn một số lần.
Lực lượng cốt lõi thực hiện những nhiệm vụ này chính là dòng vi mạch Ascend của Huawei. Đến cuối năm 2025, số lượng nhà phát triển sinh thái Ascend đã vượt qua con số 4 triệu, số đối tác hợp tác vượt qua 3000 doanh nghiệp, 43 mô hình lớn trong ngành dựa trên Ascend đã hoàn thành huấn luyện trước, hơn 200 mô hình nguồn mở đã được điều chỉnh. Tại hội nghị lớn MWC ngày 2 tháng 3 năm 2026, Huawei còn tung ra SuperPoD, nền tảng tính toán thế hệ mới hướng tới thị trường quốc tế.
Khoái Số 910B của Ascend đã có hiệu suất FP16 tương đương với NVIDIA A100. Mặc dù khoảng cách vẫn tồn tại, nhưng đã từ trạng thái không sử dụng chuyển sang trạng thái sử dụng, từ sử dụng đến đang trở nên hữu ích. Việc xây dựng hệ sinh thái không thể chờ cho đến khi chip hoàn hảo mới bắt đầu, phải mở rộng quy mô lớn ngay từ giai đoạn đủ sử dụng, sử dụng nhu cầu kinh doanh thực tế để thúc đẩy việc cập nhật liên tục của chip và phần mềm. Mục tiêu nhập khẩu máy chủ có khả năng tính toán nội địa của ByteDance, Tencent và Baidu, dự kiến tăng gấp đôi vào năm 2026 so với năm trước. Dữ liệu từ Bộ Công nghiệp và Công nghệ Thông tin Trung Quốc cho thấy, quy mô tính toán thông minh của Trung Quốc đã đạt 1590 EFLOPS. Trong năm 2026, đang trở thành năm thành lập quy mô tính toán nội địa.
Vào đầu năm 2026, tiểu bang Virginia, nơi chịu trách nhiệm cho lưu lượng dữ liệu trung tâm toàn cầu lớn, đã tạm ngừng phê duyệt các dự án xây dựng trung tâm dữ liệu mới. Georgia đã tiếp tục, tạm ngừng phê duyệt cho đến năm 2027. Illinois và Michigan cũng lần lượt áp đặt các biện pháp hạn chế.
Theo dữ liệu từ Cơ quan Năng lượng Quốc tế, vào năm 2024, lượng điện tiêu thụ của các trung tâm dữ liệu tại Mỹ đã đạt 183 terawatt-giờ, chiếm khoảng 4% tổng lượng điện tiêu thụ của cả nước. Đến năm 2030, con số này dự kiến sẽ tăng gấp đôi lên 426TWh, có thể chiếm hơn 12%. Giám đốc điều hành của công ty Arm đã dự đoán rằng đến năm 2030, trung tâm dữ liệu AI sẽ tiêu tốn 20% đến 25% lượng điện của Mỹ.
Mạng lưới điện của Mỹ đã không thể chịu đựng. Mạng lưới điện PJM phục vụ 13 tiểu bang ở miền Đông Hoa Kỳ đang đối mặt với thiếu hụt năng lực 6GW. Đến năm 2033, toàn bộ Mỹ sẽ phải đối mặt với thiếu hụt năng lực điện 175GW, tương đương với nhu cầu điện lượng của 130 triệu hộ gia đình. Chi phí bán buôn điện tại các khu vực tập trung trung tâm dữ liệu đã tăng 267% so với năm trước đó.
Đích thực của sức mạnh tính toán là nguồn năng lực. Trên chiều này, khoảng cách giữa Trung Quốc và Mỹ lớn hơn cả vấn đề chip, chỉ khác là hướng đã bị đảo ngược.
Lượng điện sản xuất hàng năm của Trung Quốc là 10,4 nghìn tỷ kWh, Mỹ là 4,2 nghìn tỷ kWh, Trung Quốc là 2,5 lần Mỹ. Quan trọng hơn, việc sử dụng điện sinh hoạt của cư dân tại Trung Quốc chỉ chiếm 15% tổng lượng tiêu thụ điện, trong khi tỷ lệ này tại Mỹ là 36%. Điều này có nghĩa là Trung Quốc có một lượng điện công nghiệp dự phòng lớn hơn nhiều so với Mỹ để đầu tư vào xây dựng cơ sở tính toán.
Trên mặt giá điện, giá điện tại khu vực tập trung công ty AI ở Mỹ dao động từ 0,12 đến 0,15 đô la mỗi kWh, trong khi giá điện công nghiệp ở Tây Trung Quốc khoảng 0,03 đô la, chỉ bằng một phần tư đến một phần năm của Mỹ.
Tăng trưởng lượng điện sản xuất của Trung Quốc đã đạt 7 lần so với Mỹ.
Khi Mỹ đang lo lắng về vấn đề cung cấp điện, trí tuệ nhân tạo của Trung Quốc đang âm thầm ra khơi. Nhưng lần này, việc ra khơi không phải là sản phẩm, không phải là nhà máy, mà là Token.
Token, đơn vị nhỏ nhất của mô hình trí tuệ nhân tạo xử lý thông tin, đang trở thành một loại hàng hoá kỹ thuật số mới. Nó được sản xuất từ nhà máy sức mạnh tính toán của Trung Quốc, và được vận chuyển đến toàn cầu qua cáp quang dưới biển.
Dữ liệu phân phối người dùng của DeepSeek có thể giải thích vấn đề rất rõ ràng: Trung Quốc chiếm 30,7%, Ấn Độ 13,6%, Indonesia 6,9%, Mỹ 4,3%, Pháp 3,2% trong số đó. Nó hỗ trợ 37 ngôn ngữ, phổ biến tại các thị trường mới nổi như Brazil. Trên toàn thế giới, có 26.000 doanh nghiệp đã mở tài khoản, 3.200 tổ chức triển khai phiên bản doanh nghiệp.
Vào năm 2025, 58% các công ty khởi nghiệp AI mới đã tích hợp DeepSeek vào ngăn xếp công nghệ của họ. Ở Trung Quốc, DeepSeek chiếm 89% cổ phần thị trường. Trong khi ở các quốc gia bị trừng phạt khác, cổ phần thị trường dao động từ 40% đến 60%.
Cảnh tượng này rất giống với cuộc chiến khác về quyền lực chủ đạo ngành công nghiệp trước đây bốn mươi năm trước.
Vào năm 1986 tại Tokyo, dưới áp lực mạnh mẽ từ Mỹ, Chính phủ Nhật Bản đã ký kết "Hiệp định Bán dẫn Mỹ-Nhật". Ba điều khoản cơ bản của hiệp định bao gồm: yêu cầu Nhật Bản mở cửa thị trường bán dẫn, cổ phần thị trường chip của Mỹ tại Nhật Bản phải đạt 20% trở lên; cấm nghiêm ngặt việc xuất khẩu bán dẫn của Nhật Bản dưới giá thành; áp đặt mức thuế phạt 100% cho việc xuất khẩu 300 triệu USD chip của Nhật Bản. Đồng thời, Mỹ đã từ chối việc Fujitsu mua lại Fairchild Semiconductor.
Năm đó, ngành công nghiệp bán dẫn của Nhật Bản đang ở đỉnh cao. Vào năm 1988, Nhật Bản đã chiếm 51% cổ phần thị trường chip toàn cầu, trong khi Mỹ chỉ có 36,8%. Trong số 10 công ty bán dẫn lớn nhất trên thế giới, Nhật Bản chiếm 6 vị trí: NEC đứng thứ hai, Toshiba thứ ba, Hitachi thứ năm, Fujitsu thứ bảy, Mitsubishi thứ tám, Panasonic thứ chín. Vào năm 1985, Intel đã lỗ 173 triệu USD trong cuộc đua chip Mỹ-Nhật, đứng trước nguy cơ phá sản.
Nhưng sau khi ký kết hiệp định, mọi thứ đã thay đổi.
Mỹ đã tiến hành áp đặt ái lực toàn diện lên các doanh nghiệp bán dẫn Nhật Bản thông qua các biện pháp như điều tra 301. Đồng thời, hỗ trợ Samsung của Hàn Quốc và Hynix với giá cả thấp hơn để tấn công thị trường Nhật Bản. Cổ phần thị trường DRAM của Nhật Bản đã giảm từ 80% xuống còn 10%. Đến năm 2017, cổ phần thị trường IC của Nhật chỉ còn 7%. Các ông lớn từng vô song trước đây, đã hoặc bị chia tách, hoặc bị mua lại, hoặc bị đẩy vào cuộc chạy đua thua lỗ không ngừng.
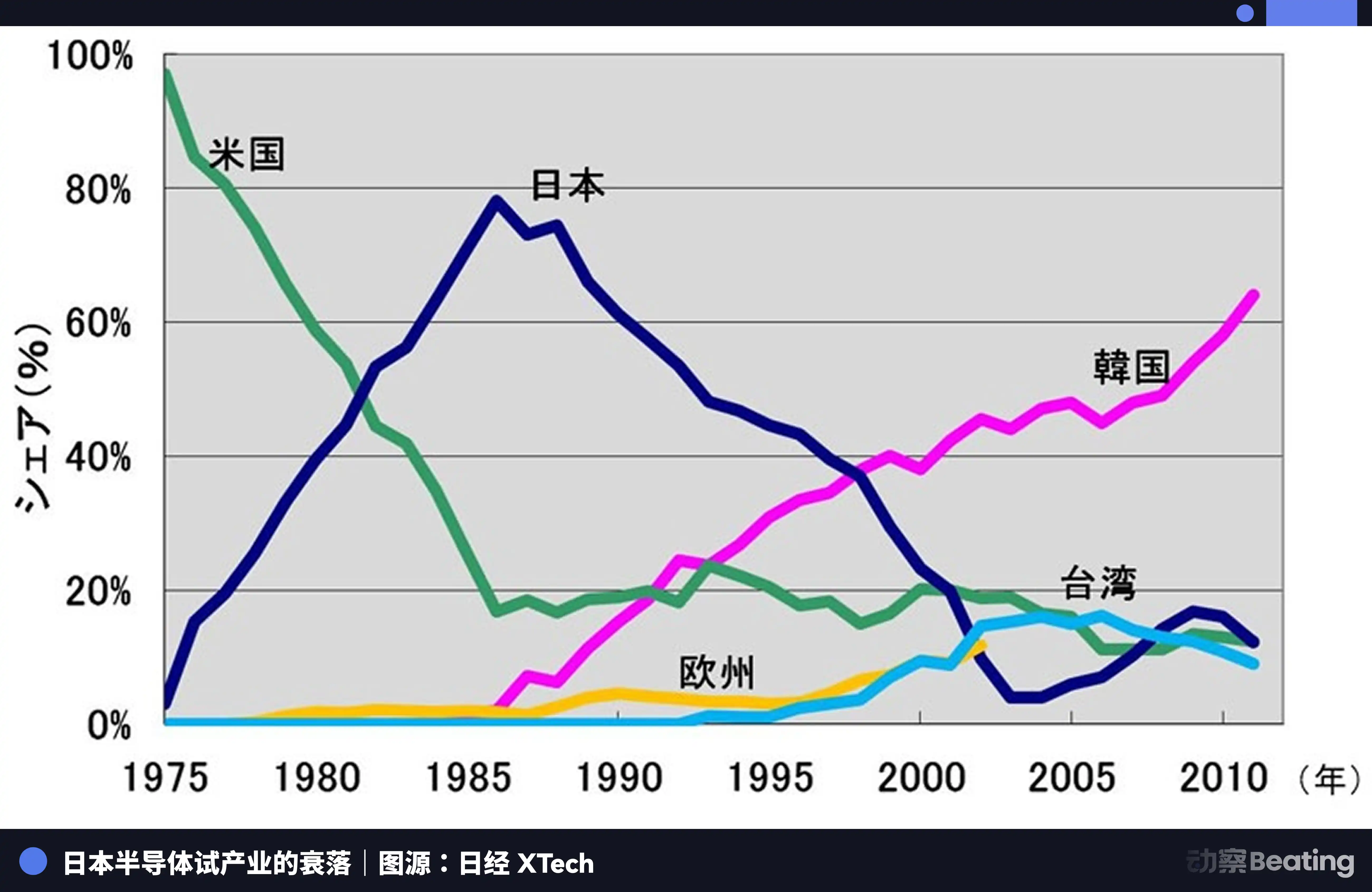
Bi kịch của ngành công nghệ bán dẫn của Nhật Bản đến từ việc họ hài lòng với việc trở thành một nhà sản xuất tốt nhất trong một hệ thống phân chia lao động toàn cầu do một lực lượng bên ngoài duy nhất điều hành, nhưng họ chưa bao giờ nghĩ đến việc xây dựng một hệ sinh thái độc lập của riêng mình. Khi triều cường rút lui, họ mới nhận ra rằng ngoài việc sản xuất, họ không có gì.
Ngày nay, ngành công nghiệp Trí tuệ Nhân tạo của Trung Quốc đứng ở một ngã đường tương tự nhưng hoàn toàn khác biệt.
Tương tự ở chỗ, chúng ta đều đối mặt với áp lực lớn từ bên ngoài. Kiểm soát chip ba ngành, ngày càng tăng cường, và rào cản của hệ sinh thái CUDA vẫn cao chót vót.
Khác biệt ở chỗ, lần này, chúng ta đã chọn một con đường khó khăn hơn. Từ tối ưu cực đại ở mức độ thuật toán, đến sự vượt trội của chip công nghệ trong nước từ triển khai đến huấn luyện, tiếp tục đến sự tích luỹ của 4 triệu nhà phát triển trong cộng đồng Seerene, và đến việc Token ra khơi để thâm nhập vào thị trường toàn cầu. Mỗi bước trên con đường này, đều đang xây dựng một hệ sinh thái công nghiệp độc lập mà Nhật Bản ngày xưa chưa bao giờ sở hữu.
Ngày 27 tháng 2 năm 2026, ba báo cáo hiệu suất từ ba công ty chip Trí tuệ Nhân tạo trong nước được công bố vào cùng một ngày.
Cambricon, doanh thu tăng đột ngột 453%, lần đầu tiên đạt lãi ròng hàng năm. MoorThread, doanh thu tăng 243%, nhưng tổng lỗ 1 tỷ. DeePhi, doanh thu tăng 121%, tổng lỗ gần 8 tỷ.
Nửa còn lại là lửa, nửa còn lại là nước biển.
Lửa, là sự khát khao cực độ của thị trường. 95% không gian mà Hoàng Nhân Hùn nhường lại, đang dần bị các con số doanh thu của các công ty trong nước này, từng chút một, lấp đầy. Dù hiệu suất ra sao, dù sinh thái thế nào, thị trường đều cần có một lựa chọn thứ hai ngoài NVIDIA. Đây là cơ hội cấu trúc hiếm có một thời kỳ được giải mở bởi các yếu tố địa chính trị.
Nước biển, là chi phí xây dựng hệ sinh thái lớn lao. Mỗi khoản lỗ, đều là tiền bạc thật sự mà phải trả để đuổi kịp hệ sinh thái CUDA. Đó là vốn nghiên cứu và phát triển, là tiền thưởng phần mềm, là chi phí lao động của các kỹ sư được gửi đến hiện trường của khách hàng, giải quyết từng vấn đề biên dịch một cách cụ thể. Những khoản lỗ này, không phải là do quản lý kém cỏi, mà là thuế chiến tranh mà cần phải trả để xây dựng một hệ sinh thái độc lập.
Ba báo cáo này, so với bất kỳ báo cáo ngành nghề nào, tất cả đều ghi nhận một cách chân thực hơn về bản chất của cuộc chiến sức mạnh tính toán này. Đó không phải là một chiến thắng mạnh mẽ, mà là một trận chiến dữ dội, khi mà máu chảy trong mỗi bước tiến.
Nhưng hình thức của cuộc chiến, quả thực đã thay đổi. Tám năm trước, chúng ta thảo luận về vấn đề "sống sót được không". Ngày nay, chúng ta thảo luận về vấn đề "sống sót mất phải trả giá như thế nào".
Chính giá trị đó, chính là sự tiến bộ.
Tin tức nóng